Konfiguracja rozpoznawania mowy, parametry audio i wersje robocze robotów
Efektywność Robota głosowego w 90% zależy od jego zdolności do precyzyjnego rozumienia klienta, który mówi w różnych językach lub z różną prędkością. W UniTalk zintegrowaliśmy zaawansowane ustawienia rozpoznawania mowy (oparte na technologii Google), które pozwalają zarządzać dwoma językami jednocześnie, konfigurować czułość oraz szybkość uzyskiwania wyników. Ponadto otrzymujesz elastyczne narzędzie do tworzenia audio: od dynamicznej syntezy mowy (TTS) opartej na parametrach połączenia, po wykorzystanie SSML i pauz. Zapewnia to maksymalnie naturalny dialog i gwarantuje, że żaden bilingwalny klient nie zostanie pominięty.
W jaki sposób robot wybiera wyniki rozpoznawania, jeśli w ustawieniach rozpoznawania określono dwa języki?
System rozpoznawania Google wysyła wyniki pośrednie, gdy subskrybent mówi, a po około 1,5-2,5 sekundy, gdy subskrybent skończy mówić, wysyła ostateczny wynik rozpoznawania.
Wybrany zostanie język, dla którego ostateczny wynik zostanie odebrany jako pierwszy. Jeśli wynik zostanie wysłany dla obu języków w tym samym czasie, wybrany zostanie język o najwyższej dokładności procentowej określonej przez Google.
Jeśli w ustawieniach rozpoznawania mowy włączono opcję „Nie czekaj na wynik końcowy”, a ostatni wynik pośredni nadszedł ponad 2 sekundy temu, zostanie on uznany za wynik końcowy.
Ustawienia rozpoznawania mowy subskrybenta są tworzone na stronie ustawień. Obecnie dostępny jest tylko system rozpoznawania Google.
Ustawienia ogólne
- Nazwa – nazwa profilu
- Ustawianie głównego języka
- Ustawianie języka alternatywnego
- Język alternatywny nie musi być taki sam jak język główny i nie jest konieczne jego określanie. Opłata za rozpoznanie języka alternatywnego jest naliczana oddzielnie.
Funkcje rozpoznawania Google
- Google ma języki, które obsługują zaawansowane rozpoznawanie (dostosowane do połączeń telefonicznych) i te, które tego nie robią.
- Lista języków dostępnych do wyboru w ustawieniach:
- Angielski (USA) – obsługuje ulepszone rozpoznawanie
- Angielski (GB) – obsługuje ulepszone rozpoznawanie
- Ukraiński
- Rosyjski – obsługuje ulepszone rozpoznawanie
- Polski
- Jeśli potrzebujesz języka, którego nie ma na liście, skontaktuj się z pomocą techniczną.
- Podczas rozpoznawania Google wysyła pośrednie wyniki, gdy rozmówca mówi, a ostateczny wynik po chwili.
- W przypadku języków, które obsługują rozszerzone rozpoznawanie (rosyjski, angielski), ostateczny wynik pojawia się około 2 sekundy po zakończeniu mówienia przez abonenta.
- W przypadku języków, które nie obsługują rozszerzonego rozpoznawania (ukraiński, polski), sytuacja jest niestabilna: ostateczny wynik może pojawić się 2 sekundy lub nawet minutę później.
Ustawienia:
- Użyj zaawansowanego modelu rozpoznawania. Dostępne tylko dla języków z zaawansowanym rozpoznawaniem. Przyspiesza wynik końcowy o około 10%, ale wyniki pośrednie są mniej dokładne.
- Nie czekaj na wynik końcowy. Jeśli w ciągu 2 sekund od otrzymania wyniku pośredniego nie otrzymamy innego wyniku pośredniego lub końcowego, wynik zostanie zaakceptowany przez robota głosowego bez oczekiwania na wynik końcowy. To ustawienie zostało dodane specjalnie dla języków, które nie obsługują zaawansowanego rozpoznawania. Nie zalecamy włączania go dla języków, które obsługują zaawansowane rozpoznawanie.
Funkcje audio
Można określić audio i alternatywne audio nie tylko jako pojedynczy projekt audio, ale jako zestaw części.
Częściami audio mogą być:
- projekt audio

Aby dźwięk był dostępny dla robotów głosowych, należy go przesłać w sekcji „Roboty głosowe” na stronie audio. Maksymalna możliwa długość dźwięku to 5 minut; jeśli jest dłuższy, zostanie obcięty po przesłaniu.
- cisza
Maksymalny możliwy czas trwania ciszy wynosi 10 000 milisekund (10 sekund).
- synteza mowy

– Synthesise value – wybierz wartość do zsyntetyzowania. Syntezowane mogą być dane określone w numerach robotów głosowych: nazwa, notatka, parametry od 1 do 10, dane dla Web Dialer
– Synteza mowy działa tylko w przypadku połączeń z robotem głosowym. Robot głosowy syntezuje cały dźwięk w robocie i jego dialogi w tle przed wywołaniem abonenta
– Ustawienie „Jeśli synteza audio nie powiedzie się” określa, co dzieje się w przypadku nieudanej syntezy.

– Zakończ połączenie – jeśli co najmniej jeden dźwięk nie został zsyntetyzowany, robot nie zadzwoni do abonenta.
– Pomiń dźwięk – części dźwięku, których nie udało się zsyntetyzować, zostaną pominięte podczas odtwarzania dźwięku abonentowi.
Jeśli dla części dźwięku nie wybrano żadnych ustawień syntezy mowy, użyte zostaną ustawienia syntezy mowy określone w głównych ustawieniach robota.
Jeśli parametr, który ma zostać zsyntetyzowany, nie jest obecny, ta część dźwięku zostanie pominięta podczas odtwarzania. Na przykład, gdy synteza określa, że chcesz zsyntetyzować nazwę z numeru połączenia, ale nazwa nie jest określona.
Jeśli wartość do zsyntetyzowania zaczyna się i kończy na , zostanie ona zsyntetyzowana jako tekst SSML, a nie zwykły tekst.

Na przykład tutaj możesz zobaczyć jeden dźwięk, który składa się z czterech części. Po odtworzeniu dźwięku subskrybent najpierw usłyszy dźwięk projektu „Dzień dobry”, następnie 0,2 sekundy ciszy, następnie zsyntetyzowany dźwięk z wartością określoną w polu „Nazwa”, a na końcu dźwięk projektu „Promocja”.
Projekty robotów
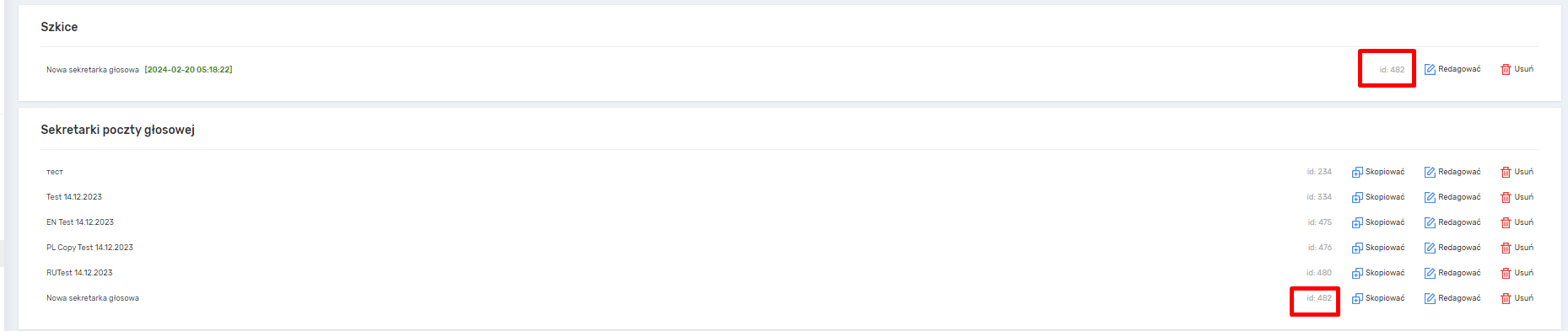
Podczas edycji robota niezapisane zmiany są zapisywane w wersjach roboczych. Listę wersji roboczych można znaleźć na stronie Roboty głosowe w sekcji Wersje robocze. Po zapisaniu robota wersja robocza jest automatycznie usuwana. Wersje robocze są powiązane z przeglądarką i mogą być przeglądane tylko przez użytkownika. Maksymalna liczba zapisanych wersji roboczych wynosi 3.
Wersje robocze są zapisywane za każdym razem, gdy zmieniasz robota i gdy przechodzisz między wersjami robota w edytorze za pomocą strzałek, z wyjątkiem sytuacji, gdy strzałka w lewo jest nieaktywna (w takim przypadku nie są wprowadzane żadne zmiany).

Na stronie Voice Robots można usuwać i wyświetlać wersje robocze. Każda wersja robocza zawiera identyfikator robota, do którego należy. Jeśli id=0, jest to wersja robocza robota, który nie został jeszcze zapisany i nie przypisano mu identyfikatora.
Jeśli przejdziesz do wersji roboczej i zapiszesz ją, zmiany zostaną zapisane w robocie o tym samym identyfikatorze, chyba że id=0, w którym to przypadku zostanie utworzony nowy robot. Na przykład:

Wersja robocza i robot Window mają ten sam identyfikator. Jeśli przejdziesz do wersji roboczej i klikniesz Zapisz, zmiany zostaną zastosowane do robota Window, a wersja robocza Window zostanie automatycznie usunięta.
Inne ustawienia
- Gdzie mogę określić język w ustawieniach robota?
Języki, w których otrzymujemy rozpoznane słowa rozmówcy, są określone w ustawieniach rozpoznawania mowy. Są one określone w głównych ustawieniach robota. W warunkach przejściowych frazy, słowa itp. muszą być zapisane w tych samych językach, które zostały określone w ustawieniach rozpoznawania mowy.
- Kiedy zostaną dodane nowe wersje, do których będzie można powrócić za pomocą przycisku Cofnij?
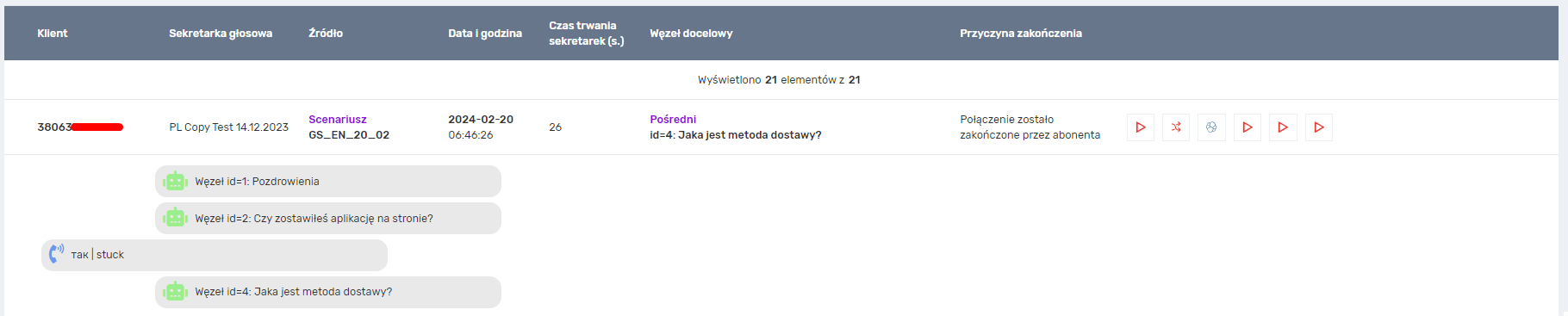
– Podczas dodawania węzła
– Podczas usuwania węzła
– po kliknięciu przycisku Zastosuj zmiany na pasku bocznym ustawień (tj. po zapisaniu podstawowych ustawień robota, zapisaniu warunków węzła, zapisaniu ustawień akcji węzła)
– Podczas wklejania węzłów po skopiowaniu lub wycięciu
– Po zmianie koloru paska bocznego węzła
– Po przesunięciu węzła w lewo lub w prawo na liście dzieci węzła nadrzędnego
Po zapisaniu robota nie można cofnąć zmian – wersje pośrednie są tracone.
- Podmioty określone w pracy głosowej nie mogą zostać usunięte z projektu.
Dotyczy to:
- Skrypty
- Menu głosowych
- Działy
- Dźwięk robotów głosowych
- Dzwonki zawieszone
- Programy obsługi zdarzeń
- Roboty działające w tle
- Profile środowiska robota głosowego
- Profile ustawień rozpoznawania mowy
W przypadku usunięcia numeru wewnętrznego z projektu, jeśli został on określony w działaniach robotów głosowych z typem „Przeniesienie połączenia na linię SIP”, typ działania zostanie zmieniony na „Wyjście z robota głosowego”.
W historii połączeń roboty głosowe są wyświetlane jako pojedynczy krok przekierowania połączeń. Roboty w tle nie są uwzględniane w przekierowaniach połączeń, są uważane za część głównego robota.
Precyzyjna konfiguracja rozpoznawania mowy oraz elastyczność w pracy z plikami audio to klucz do stworzenia wysoce adaptacyjnego Robota głosowego. Wykorzystując dwa języki rozpoznawania oraz indywidualne ustawienia (takie jak „Nie czekaj na końcowy wynik” dla mniej stabilnych języków), minimalizujesz opóźnienia i zapewniasz najwyższą dokładność. Możliwość tworzenia audio z elementów dynamicznych (TTS z parametrów) pozwala na natychmiastową personalizację połączeń. Dodatkowo, system wersji roboczych gwarantuje, że Twoje niedokończone zmiany będą zawsze zapisane i chronione przed przypadkową utratą.
BEZPŁATNA KONSULTACJA